
Telcos no longer run AI in one neat data centre. They run it across towers, central offices, regional sites, and cloud zones. That spread creates a hard problem: how do you manage all of it as one platform without losing control of latency, cost, GPUs, or data rules?
That is where AI Grid Orchestration fits. It places workloads where they make the most sense, then keeps policy, scaling, and recovery aligned across the estate. NVIDIA AI Grid Orchestration is now a clear reference point for this model, as recent telecom AI grid deployments show. For telcos that also need sovereign control, stack8s project AiK Edge (part of the NVIDIA Inception Program) offers a Kubernetes-based way to run mixed infrastructure through one control plane.
What AI Grid Orchestration means for a telco edge network
In plain English, AI Grid Orchestration is the control layer for distributed AI. It does far more than push an app into production. It decides where a model should run, scales it when demand rises, applies policy, watches health, and restores service after faults. In a telco, that spans 5G edge nodes, points of presence, central offices, and regional data centres. Think of it like air traffic control for AI, because every workload has a best route, a best landing spot, and rules it must follow.

From scattered edge sites to one usable AI fabric
Without orchestration, each site becomes its own mini-project. One location has spare GPUs, another has better latency, and a third must keep data in-region. Soon, operations teams are juggling exceptions instead of running a platform. AI Grid Orchestration turns that patchwork into one operating model.
Placement becomes policy-led. A workload can stay near the user for response speed, move to a regional hub for lower cost, or avoid a degraded site if health drops. As a result, telcos can support low-latency AI services, automate network decisions, and launch enterprise edge offers without treating every location as a special case.
Where Nvidia AI Grid Orchestration fits into the picture
NVIDIA's approach gives the market a practical frame for distributed inference. It watches GPU use, memory, network conditions, power, heat, and policy, then routes jobs across hubs and edge nodes. That matters when traffic spikes are uneven and hardware is limited.
For telcos, it's a strong reference architecture. Stack8s can complement that model by adding Kubernetes-based control across hybrid, sovereign, and on-prem environments, where one vendor stack rarely covers the full estate.
The biggest edge AI problems telcos face, and how stack8s helps solve them
The edge sounds simple until production starts. Then the real issues appear: tight latency targets, costly GPUs, local data rules, mixed hardware, and too many tools. Telco teams don't need more moving parts. They need one way to run them.
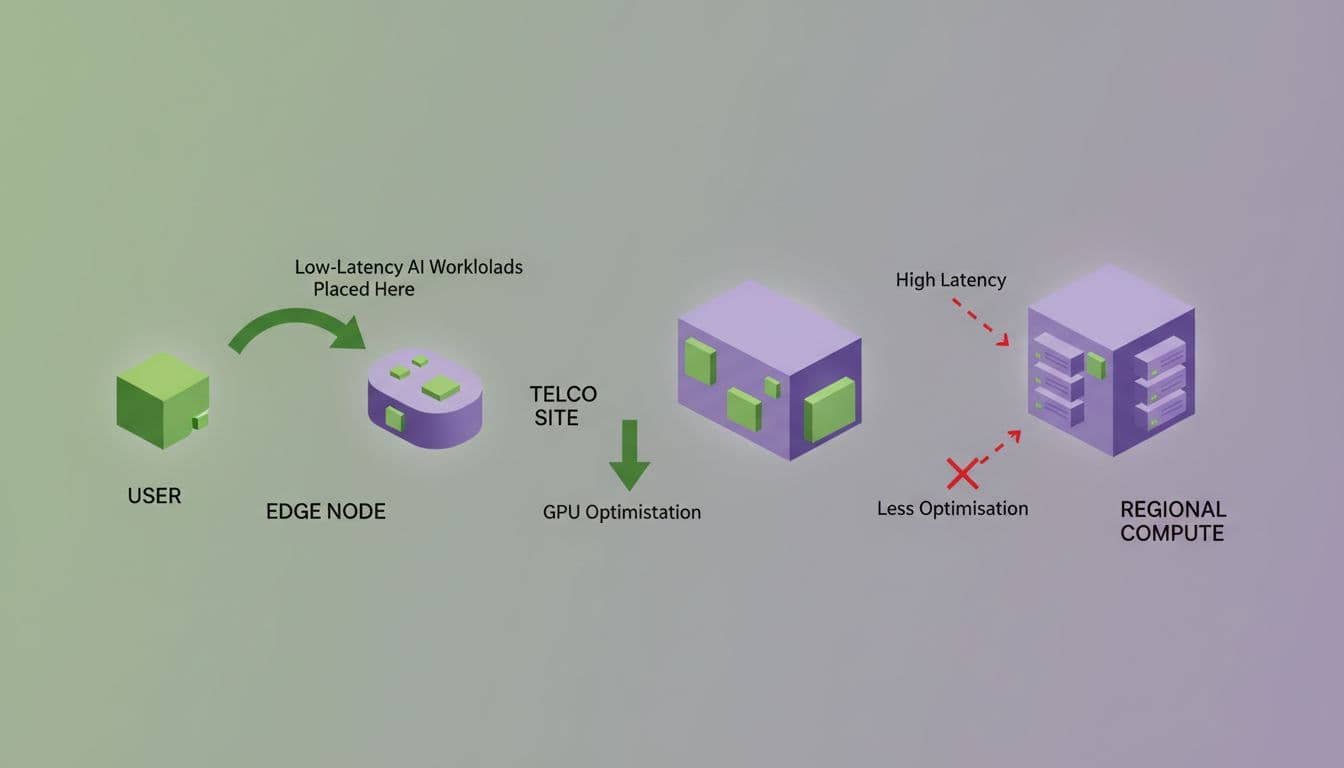
Keeping latency low without wasting GPUs
Some AI jobs must stay close to users. Voice services, video analytics, fraud checks, and network response loops can't wait for a distant region. Yet other work, such as batch inference, retraining steps, or offline analysis, can run farther away for less money.
Stack8s helps place and move workloads across cloud, on-prem, and edge nodes under one control plane. So teams can keep millisecond-sensitive inference local, while shifting less urgent work to cheaper capacity. That improves GPU use and lowers spend. It also matches the direction seen in Akamai's AI Grid rollout, where distributed inference is routed across edge, regional, and core locations.
Meeting sovereignty, security, and multi-tenant needs
Telcos often carry several trust zones at once. Internal network teams need protected access. Enterprise customers want private AI. Partners may need isolated projects on the same platform. At the same time, data may need to stay in-country or within a named region.
That is where stack8s has a strong fit. Its sovereign deployment model, private registries, regional redundancy, and zero-trust posture support policy-led operations. In other words, telcos can host private AI services without giving up control of where data, models, and logs live.
Running thousands of sites without operational sprawl
Scale breaks manual processes first. Updates drift. Patches land unevenly. One vendor exposes one dashboard, another exposes three, and outage recovery becomes slower than it should be. Mixed hardware makes it worse.
If every edge site behaves differently, the edge never becomes a platform.
Stack8s leans on Kubernetes, GitOps, and a single portal to standardise roll-outs, patching, monitoring, and recovery. That gives telcos a more consistent way to manage varied edge footprints, even when the sites and suppliers don't match.
Why stack8s AiK Edge is a strong fit for AI Grid Orchestration in telco environments
A telco AI platform has to do two jobs at once. It must be flexible for platform teams, yet controlled enough for security, policy, and uptime. Stack8s fits because it joins sovereign cloud control with Kubernetes orchestration and AI-ready infrastructure support.
One control plane across cloud, on-prem, and far-edge sites
The stack8s Spine fabric links compute across more than one provider into a unified Kubernetes control plane. That means telcos can provision GPUs, CPUs, and storage across public cloud, private infrastructure, and far-edge sites, then move workloads without lock-in. The stack8s Network Fabric spans across 15+ Clouds and 700 Datacenters across the globe and is built for exactly that kind of distributed control.
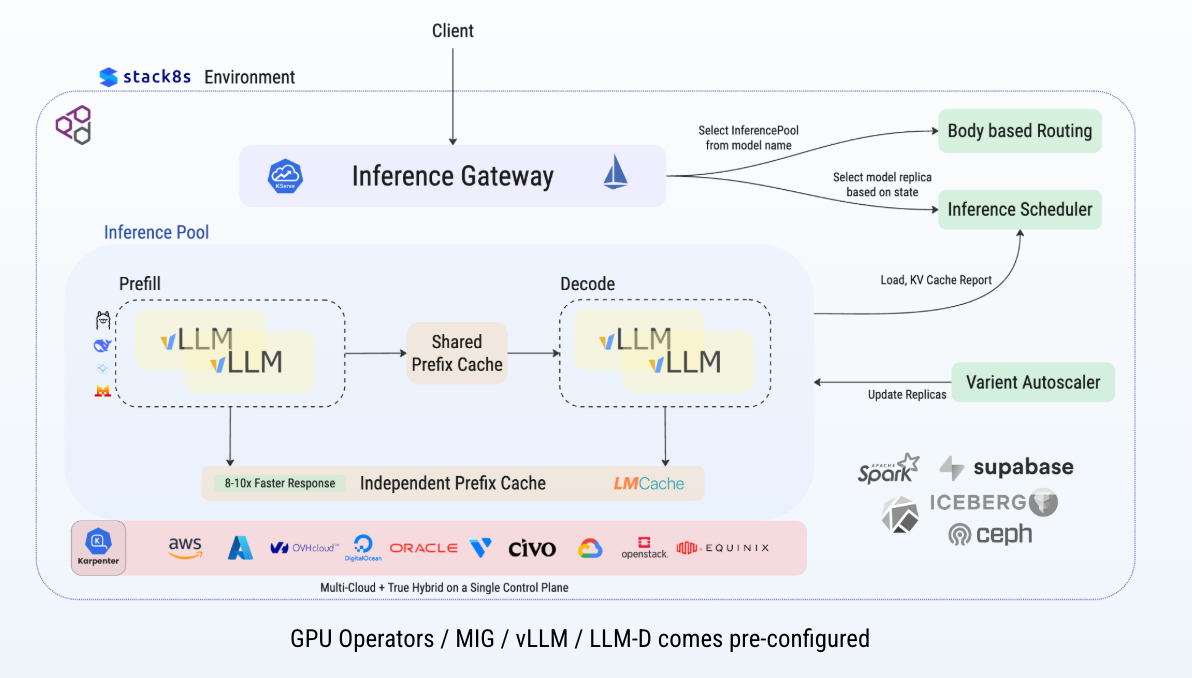
Why stack8s combines 15+ cloud infrastructures well
Most telcos already own a mixed estate. They can't stop everything and re-platform from scratch. Stack8s meets that reality with vanilla Kubernetes, hybrid clustering, and vendor flexibility across 15+ cloud and edge providers. So the platform works with what operators already have, while still giving them one place to manage projects, clusters, and AI components.
A practical path from infrastructure to revenue-ready AI services
This is where orchestration becomes commercial. Telcos can stand up private LLM services, video analytics, AI agents for network operations, and enterprise edge offers on the same base platform. The mix of stack8s and NVIDIA-style AI Grid thinking helps them build faster, keep control, and waste fewer resources.
Conclusion
The hard part of telco edge AI is not adding more compute. It's managing compute, policy, security, and placement together. NVIDIA AI Grid Orchestration shows where the market is heading, because distributed inference now needs smarter control across hubs and edge sites. Stack8s offers a practical way to do that now, with a sovereign, Kubernetes-based control plane across cloud, on-prem, and far-edge infrastructure. For telcos, that turns a messy edge estate into a usable AI platform, one that supports both internal operations and new customer-facing services.