I keep seeing founders burn weeks building shiny AI agents, then wonder why nothing sticks. The bottom line is simple: most "agents" don't create durable value, they create moving parts. When the model changes, the tool changes, the prompt breaks, and the whole thing wobbles.
I'm not saying automation is bad. I'm saying the lasting part usually isn't an agent at all. It's the plain, boring stuff you can reason about, review, version, and hand over to a team without a long meeting.
Why I'm sceptical about agents (and why you don't need to take it on faith)
My bias comes from doing work where mistakes have teeth. I spent 8 years in the Marine Corps around cryptography and intelligence, then moved into building software that touches these same kinds of systems. More recently, I've helped schools figure out AI, including training professors at my own former school. I also implement software and train large organisations, including consulting work with KPMG.
That background doesn't make me right, but it does explain why I'm allergic to fragile complexity. Agents often look like progress because they "do things". Yet in practice, they hide logic inside a conversational blob. It's hard to test, hard to audit, and even harder to keep stable when you're under pressure.
If you can't explain how it works by pointing at files in a repo, it won't survive your next scale-up.
This matters even more when the workload is expensive, like a GPU-heavy pipeline where one bad loop can torch your budget.
The best "agent" is a markdown file plus scripts
My favourite pattern is embarrassingly simple: a markdown file that defines the job, plus small scripts that do the work, routed by that markdown. It's "agentic" in outcome, without the fragile theatre.
A tiny example of what I mean:
playbooks/train_gpu.md(goal, inputs, guardrails, success checks)scripts/select_provider.py(chooses where to run)scripts/run_training.py(executes the job)scripts/report_costs.py(writes out spend and performance)
The quiet win here is that everything is visible. I can review changes in Git. I can add unit tests. I can run the same flow in CI. Most importantly, I can hand it to someone else and they can follow it like a map.
Also, folders are underrated. Clicking through a folder tree feels natural because decades of software design made it so. That's a real framework, one humans already understand.
Anthropic's stance on agentic use is also more cautious than the hype cycle suggests, which is worth reading in their own words via Claude guidance on using agents.
Sovereign cloud, vendor lockin, and the real fight: compute economics
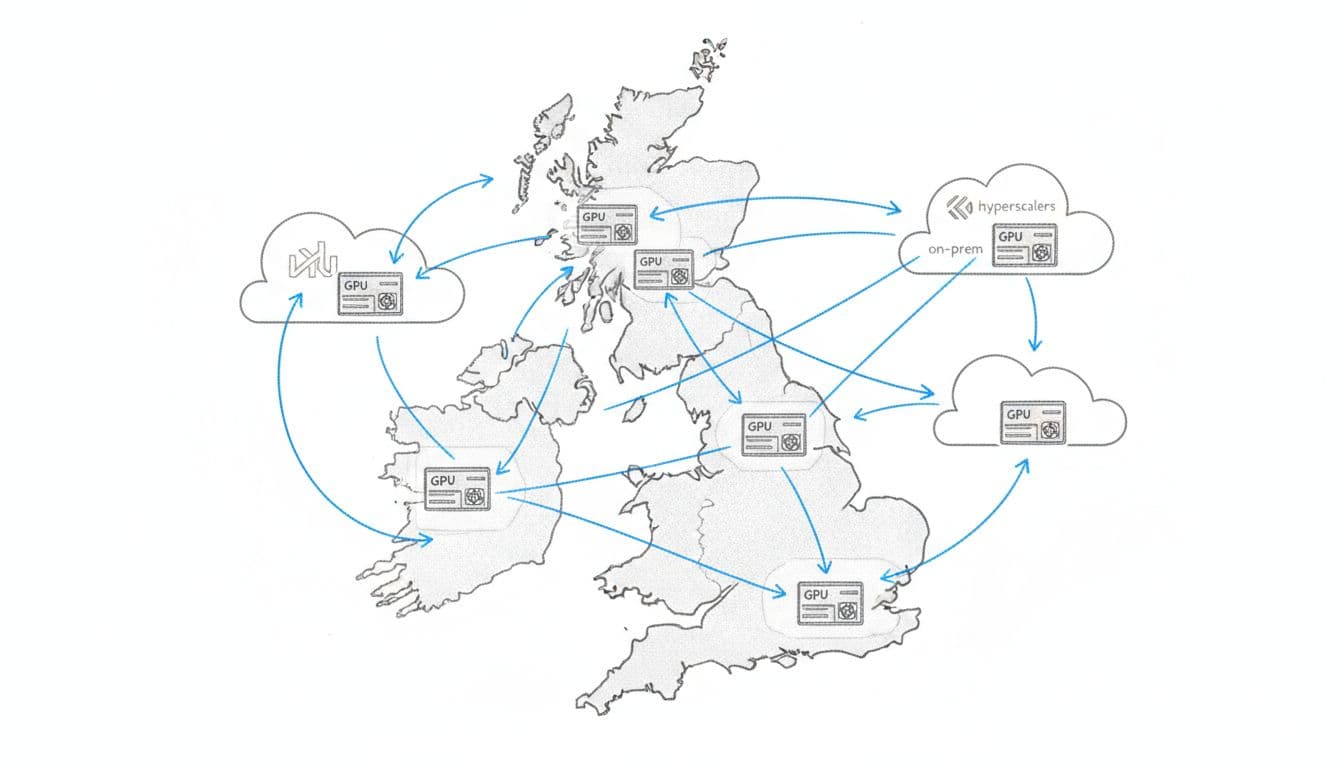
When I zoom out, most teams aren't trying to "build an agent". They're trying to ship a product while staying inside constraints: data residency, uptime, price swings, and procurement headaches.
That's where a sovereign cloud approach becomes practical, not political. You want policy-aware placement and a clear record of why a workload ran where it ran. You also want to avoid vendor lockin, because once your training stack hard-binds to one provider's quirks, switching stops being a decision and becomes a rewrite.
This is also where cost saving on compute becomes a feature, not an afterthought. With GPU workloads, the bill doesn't creep up, it jumps. A folder-based playbook plus scripts can encode the rules that matter, for example: "keep data in approved jurisdictions", "prefer cheapest GPU that meets latency", "fall back to on-prem when spot pricing spikes".
For a broader view on why control and cost can sit together, I rate the economics of a sovereign cloud.
Conclusion: build the boring core, then automate around it
I don't build for demos, I build for handovers. So I start with folders, markdown, and scripts because they last. Then, if I still need agent-like behaviour, I wrap it around that stable core. The question I keep in mind is simple: will this still work when the model changes, the provider changes, and the GPU bill is on fire? If the answer is yes, it's worth keeping. If not, it's just noise dressed up as progress.