This is an Example case study of Research Institutes - many enterprises are following suit by investing in their own on-premises infrastructure, avoiding public cloud for data sovereignty, cost control, and to prevent vendor lock-in. As organizations seek to democratize cloud capabilities, the market is shifting toward hybrid and private cloud models that blend the best of both worlds, offering flexibility, security, and significant cost benefits.
National Investment in Private HPC Infrastructure: Strategic Rationale
Nations continue to invest substantially in private high-performance computing infrastructure despite the availability of secure public cloud alternatives, driven by three fundamental strategic considerations.
National Sovereignty and Security Countries maintain significant concerns about operating sensitive research and defense applications on foreign-owned infrastructure. This reluctance stems from the potential for strategic dependencies and access vulnerabilities that could compromise national interests. By maintaining domestic control over critical computational resources, nations preserve their autonomy in conducting classified research and protecting proprietary technological developments.
Economic Efficiency for Large-Scale Operations The financial structure of private systems proves more advantageous for sustained, large-scale scientific workloads. Applications such as climate modeling and nuclear simulation require continuous access to specialized hardware configurations involving thousands of processors over extended periods. Under these operational requirements, the pay-per-use pricing model of public cloud services becomes prohibitively expensive compared to dedicated infrastructure investments.
Strategic Technology Development Building domestic HPC capabilities serves broader national objectives beyond immediate computational needs. These investments develop local expertise in critical technologies, generate high-skilled employment opportunities, and establish innovation ecosystems that enhance competitiveness in emerging fields including artificial intelligence and quantum computing. This technological foundation positions nations to maintain economic advantage in sectors that will define future global competition.
1. State of University HPC: Strengths and Gaps
Current Landscape
University HPC systems such as Stanford’s Sherlock, Cambridge’s CSD3, MIT’s SuperCloud, and others represent the pinnacle of academic computing. They deliver enormous computational power, leverage advanced scheduling (e.g., SLURM, PBS Pro), and increasingly incorporate GPUs for AI and scientific workloads.
Key strengths:
- Massive computational scale (petaflops, hundreds of thousands of CPU cores)
- High-end GPU resources (e.g., NVIDIA A100, H100, Volta, Tesla P100)
- Secure, on-premises data handling
- Customizable, institution-controlled environments
However, several gaps are becoming apparent as research and industry needs evolve:
What’s Missing: Modern Cloud-Native Tools
| Feature | Traditional University HPC | Modern Cloud / stack8s-Enabled HPC |
|---|---|---|
| GenAI/ML Model Marketplace | Rare, manual setup | Pre-integrated, on-demand |
| Database/SaaS Marketplace | Largely absent | Available via curated marketplace |
| Self-Service Provisioning | Limited | Full self-service via web portal |
| Vendor Lock-In | High (custom stack) | None (multi-cloud/on-prem) |
| Cost Control | Opaque, fixed | Transparent, optimized |
| Cloud-Native Workflow Support | Minimal | Full (K8s, Argo, Kubeflow, etc.) |
| Hybrid/Elastic Scaling | Difficult | Built-in, policy-driven |
Key Limitations
- GenAI Services: Most academic HPCs lack native support for rapid, scalable GenAI model deployment and inference.
- Marketplace of Databases/SaaS: Unlike public clouds, researchers cannot instantly access managed databases, analytics tools, or AI services.
- Self-Service & Automation: Traditional HPCs require manual provisioning and admin intervention, slowing research cycles.
- Cloud-Native Workflow Integration: Tools like Argo Workflows, Kubeflow, and Spark are hard to run efficiently on most HPCs due to architectural and policy constraints.
Why Researchers Are Craving These Features
- Faster Experimentation: GenAI, ML, and data science projects benefit from elastic, on-demand resources and a rich ecosystem of pre-integrated tools.
- Collaboration: Modern research is collaborative and cross-disciplinary, requiring seamless sharing of data, models, and workflows—something cloud-native tools facilitate.
- Cost and Efficiency: Managed services and marketplaces reduce the need for custom setup, lowering both the technical barrier and operational overhead.
2. Case Studies: University HPC Systems (with Updated Details)
| # | University | HPC System Name | Platform / Stack | Launch Date | Estimated Cost | GPU Configuration |
|---|---|---|---|---|---|---|
| 1 | University of Cambridge (UK) | CSD3 | Slurm, OpenHPC, Singularity, Lustre | 2017; upgrades in 2020, 2021, 2023 | £35 million (initial investment) | NVIDIA A100 GPUs (384 A100 GPUs in latest config) |
| 2 | University of Edinburgh (UK) | ARCHER2 | Slurm, Cray EX OS (based on SUSE Linux), Lustre | 2021 | £79 million | CPU-only system (748,544 cores) |
| 3 | Stanford University (USA) | Sherlock | Slurm, RHEL, Singularity, TensorFlow, PyTorch | 2014 (major upgrades in 2016, 2019) | $20+ million (estimated) | NVIDIA V100, RTX 2080 Ti, GTX 1080 Ti GPUs |
| 4 | MIT (USA) | SuperCloud / TX-Green | Grid Engine, MIT SuperCloud toolkit, Singularity | 2018 (SuperCloud), 2019 (TX-Green) | $2.7 million (TX-Green portion) | Over 850 NVIDIA Volta V100 GPUs |
| 5 | University of Oxford (UK) | ARC Cluster | Slurm, Ansible, Lustre, container support | 2018 (current generation) | £15+ million (estimated) | NVIDIA A100, V100, RTX A6000 GPUs |
| 6 | Univ. of Illinois Urbana-Champaign (USA) | Delta (NCSA) | Slurm, Kubernetes (hybrid), NVIDIA DGX, Lustre | 2022 | $10 million (NSF funding) | 200 NVIDIA A100 GPUs, 100 NVIDIA A40 GPUs |
| 7 | Tsinghua University (China) | Tianhe-based platforms | PBS Pro, proprietary orchestration, GPU-based stack | 2016 (current GPU cluster) | $50+ million (estimated) | NVIDIA Tesla V100, P100 GPUs (upgraded from M2050) |
| 8 | ETH Zurich (Switzerland) | Euler / Piz Daint (CSCS) | Slurm, Cray Linux Environment, Docker/Singularity | Piz Daint: 2012; upgrades in 2013, 2016, 2018 | CHF 40 million for 2016 upgrade | NVIDIA Tesla P100 GPUs (Piz Daint retired 2023) |
| 9 | Tokyo Institute of Tech (Japan) | TSUBAME 3.0 / 4.0 | PBS Pro, NVIDIA CUDA stack, Lustre, OpenMPI | TSUBAME 3.0: 2017; TSUBAME 4.0: 2024 | $15 million (TSUBAME 4.0) | TSUBAME 3.0: NVIDIA Tesla P100; TSUBAME 4.0: NVIDIA H100 GPUs |
| 10 | Univ. of Texas at Austin (USA) | Frontera (TACC) | Slurm, OpenHPC, BeeOND, Kubernetes side workloads | 2019 | $60 million (NSF funding) | RTX Quadro 5000 GPUs (limited GPU partition) |
Notable updates:
- Stanford Sherlock 4.0 (Aug 2024): 11.5+ PFLOPS, 700+ GPUs, free for Stanford researchers, hybrid ownership model.
- MIT SuperCloud: 850+ NVIDIA Volta GPUs, access tied to HPC certification.
- UIUC Delta: Full production since late 2022, hybrid Slurm/Kubernetes stack.
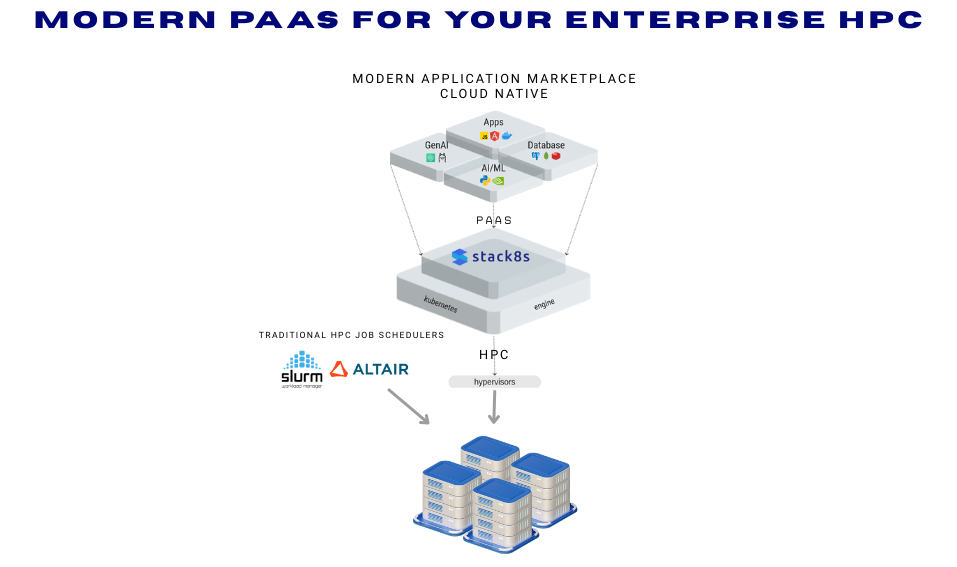
3. How stack8s and Kubernetes-Based PaaS Can Bridge the Gap
stack8s: Bringing Cloud-Native Power to On-Prem HPC
stack8s is a Kubernetes-based Platform-as-a-Service (PaaS) that enables organizations to build and scale applications across cloud, on-prem, and edge from a single control plane. Here’s how stack8s and similar solutions can address the missing needs in university HPC:
- Cloud-Native Orchestration on HPC: stack8s enables researchers to deploy containers, microservices, and GenAI workloads using familiar cloud-native workflows (kubectl, helm, Argo Workflows) on top of HPC hardware.
- Marketplace Enablement: Offers a curated marketplace of databases, AI tools, and analytics services, making it possible for researchers to instantly access and deploy the resources they need—just like on public cloud.
- No Vendor Lock-In: stack8s is designed for multi-cloud and on-prem environments, helping institutions avoid lock-in and retain control over their infrastructure and data.
- Cost Optimization: By leveraging on-prem hardware and open-source orchestration, stack8s can deliver up to 90% savings compared to public cloud, making advanced computing more accessible to budget-conscious research teams.
- Hybrid Workflows: Supports workflows that combine traditional HPC batch jobs with cloud-native pipelines, enabling seamless transitions between simulation, data processing, and AI model training.
- Self-Service and Democratization: Researchers can self-provision environments and services, accelerating innovation and reducing administrative bottlenecks.
Technical Integration: HPC + Kubernetes
Recent research demonstrates that Kubernetes can be embedded within HPC clusters, allowing users to run cloud-native workloads (e.g., Spark, ML pipelines) directly on HPC hardware without resource partitioning. Solutions like High-Performance Kubernetes (HPK) and stack8s orchestrate containers, manage storage, and integrate with HPC schedulers like Slurm, enabling researchers to use modern tools seamlessly within traditional HPC environments.
“Cloud-HPC convergence for Big Data processing pipelines that combine Cloud-native with HPC steps is most often realized with interfacing mechanisms for submitting HPC jobs from the Cloud side or vice versa… In this paper, we explore an HPC-centric solution that accommodates both Cloud and HPC software stacks on the same physical resources. We focus our work on Kubernetes, currently the most prominent distributed container orchestrator for supporting the ‘Cloud-native’ ecosystem.”
4. Conclusion: The Path Forward
Universities and enterprises alike are moving toward democratized, cloud-native computing—on their own terms. Solutions like stack8s offer a practical path to modernize HPC, bringing GenAI, marketplaces, and self-service to research without sacrificing control, security, or cost efficiency. This hybrid approach is poised to redefine how advanced computing powers the next wave of scientific discovery.
Key Takeaways:
- The future is hybrid: blending on-prem HPC with cloud-native tools.
- Democratizing cloud capabilities on-premises is the next big thing.
- stack8s and similar platforms can deliver the agility, marketplace access, and cost benefits researchers crave—without vendor lock-in.
In summary:
University HPCs are powerful but are missing the agility, self-service, and rich ecosystem of modern cloud-native platforms. Kubernetes-based PaaS solutions like stack8s can fill this gap, enabling the next generation of research and innovation—securely, cost-effectively, and without vendor lock-in.