Executive Summary
Research institutions can leverage Stack8s as a modern alternative to traditional High-Performance Computing platforms by utilizing its distributed Kubernetes infrastructure to support computational research workloads. The platform's global network fabric and cloud-native architecture offer compelling advantages over conventional HPC systems while addressing common limitations in academic computing environments.
Putting things into Perspective - Tip of the Iceberg
Here is the List of Universities with HPC's and the main question is: Why do nations continue investing billions in private supercomputers when major cloud providers offer comparable security, scalability, and computational power through their platforms?
| # | University | HPC System Name | Platform / Stack | Launch Date | Estimated Cost | GPU Configuration |
|---|---|---|---|---|---|---|
| 1 | University of Cambridge (UK) | CSD3 | Slurm, OpenHPC, Singularity, Lustre | 2017; upgrades in 2020, 2021, 2023 | £35 million (initial investment) | NVIDIA A100 GPUs (384 A100 GPUs in latest config) |
| 2 | University of Edinburgh (UK) | ARCHER2 | Slurm, Cray EX OS (based on SUSE Linux), Lustre | 2021 | £79 million | CPU-only system (748,544 cores) |
| 3 | Stanford University (USA) | Sherlock | Slurm, RHEL, Singularity, TensorFlow, PyTorch | 2014 (major upgrades in 2016, 2019) | $20+ million (estimated) | NVIDIA V100, RTX 2080 Ti, GTX 1080 Ti GPUs |
| 4 | MIT (USA) | SuperCloud / TX-Green | Grid Engine, MIT SuperCloud toolkit, Singularity | 2018 (SuperCloud), 2019 (TX-Green) | $2.7 million (TX-Green portion) | Over 850 NVIDIA Volta V100 GPUs |
| 5 | University of Oxford (UK) | ARC Cluster | Slurm, Ansible, Lustre, container support | 2018 (current generation) | £15+ million (estimated) | NVIDIA A100, V100, RTX A6000 GPUs |
| 6 | Univ. of Illinois Urbana-Champaign (USA) | Delta (NCSA) | Slurm, Kubernetes (hybrid), NVIDIA DGX, Lustre | 2022 | $10 million (NSF funding) | 200 NVIDIA A100 GPUs, 100 NVIDIA A40 GPUs |
| 7 | Tsinghua University (China) | Tianhe-based platforms | PBS Pro, proprietary orchestration, GPU-based stack | 2016 (current GPU cluster) | $50+ million (estimated) | NVIDIA Tesla V100, P100 GPUs (upgraded from M2050) |
| 8 | ETH Zurich (Switzerland) | Euler / Piz Daint (CSCS) | Slurm, Cray Linux Environment, Docker/Singularity | Piz Daint: 2012; upgrades in 2013, 2016, 2018 | CHF 40 million for 2016 upgrade | NVIDIA Tesla P100 GPUs (Piz Daint retired 2023) |
| 9 | Tokyo Institute of Tech (Japan) | TSUBAME 3.0 / 4.0 | PBS Pro, NVIDIA CUDA stack, Lustre, OpenMPI | TSUBAME 3.0: 2017; TSUBAME 4.0: 2024 | $15 million (TSUBAME 4.0) | TSUBAME 3.0: NVIDIA Tesla P100; TSUBAME 4.0: NVIDIA H100 GPUs |
| 10 | Univ. of Texas at Austin (USA) | Frontera (TACC) | Slurm, OpenHPC, BeeOND, Kubernetes side workloads | 2019 | $60 million (NSF funding) | RTX Quadro 5000 GPUs (limited GPU partition) |
Nations invest in private HPC infrastructure despite secure public clouds for three key reasons. First, national sovereignty concerns make countries reluctant to run sensitive research and defense applications on foreign-owned infrastructure, which could create strategic dependencies and potential access vulnerabilities. Second, the economics favor private systems for large-scale scientific workloads that require sustained access to specialized hardware configurations - the pay-per-use cloud model becomes prohibitively expensive for applications like climate modeling or nuclear simulation that run continuously on thousands of processors. Third, building domestic HPC capabilities serves broader strategic goals by developing local expertise in critical technologies, creating high-skilled jobs, and establishing innovation ecosystems that drive competitiveness in AI, quantum computing, and other emerging fields that will define future economic advantage.
Data Sovereignity in The Middle East
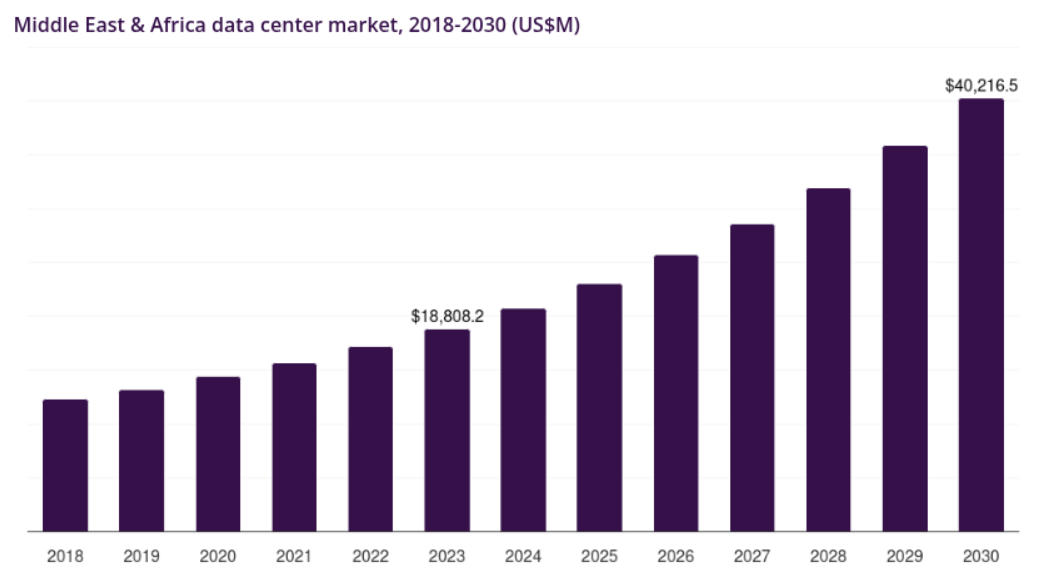
The Middle East has emerged as a pivotal player in the global AI compute and data sovereignty landscape, with Gulf nations positioning themselves as strategic bridges between technological advancement and national security imperatives. Saudi Arabia announced over $14.9 billion in AI investments at the LEAP 2025 conference, while the kingdom's reported $40 billion artificial intelligence investment fund represents one of the largest sovereign commitments to AI infrastructure globally. The UAE has similarly accelerated its investments, with Saudi Arabia and the UAE rushing to build infrastructure as they vie to become the regional tech superpower. This competition has catalyzed the development of sovereign cloud capabilities that address both regional data residency requirements and global AI compute demands. du, one of the largest telecommunications operators in the Middle East, is deploying Oracle Alloy to offer cloud and sovereign AI services to business, government, and public sector organizations in the United Arab Emirates, while Google Cloud has partnered with CNTXT to offer Sovereign Controls by CNTXT in Saudi Arabia.
The region's approach to data sovereignty is becoming increasingly sophisticated, with Saudi Arabia poised to be the first G20 nation to establish a comprehensive legal framework focusing on the establishment of sovereign data centres. This strategic positioning allows Middle Eastern nations to serve as trusted intermediaries for organizations requiring AI capabilities while maintaining strict data governance standards, ultimately reshaping global AI infrastructure patterns and establishing the region as an essential hub for sovereign AI services.
Stack8s Applications in Research Environments
Distributed Computing for Research Workloads
Stack8s enables research institutions to create distributed computing clusters that span multiple locations, including on-premises facilities, cloud resources, and partner institutions. This approach allows researchers to access computational resources beyond the constraints of a single physical HPC cluster, supporting large-scale simulations, data analysis, and collaborative research projects that require significant computational power.

Multi-Cloud Research Collaboration
The platform facilitates seamless collaboration between institutions by connecting research computing resources across different cloud providers and on-premises infrastructure. Researchers can share computational resources, datasets, and analysis tools through Stack8s-Portal while maintaining security and compliance requirements specific to academic institutions.

Containerized Research Applications
Stack8s supports containerized research applications through its Kubernetes foundation, enabling researchers to package their computational workflows, dependencies, and environments into portable containers. This approach improves reproducibility in research computing and simplifies the deployment of complex scientific software stacks across different computing environments.
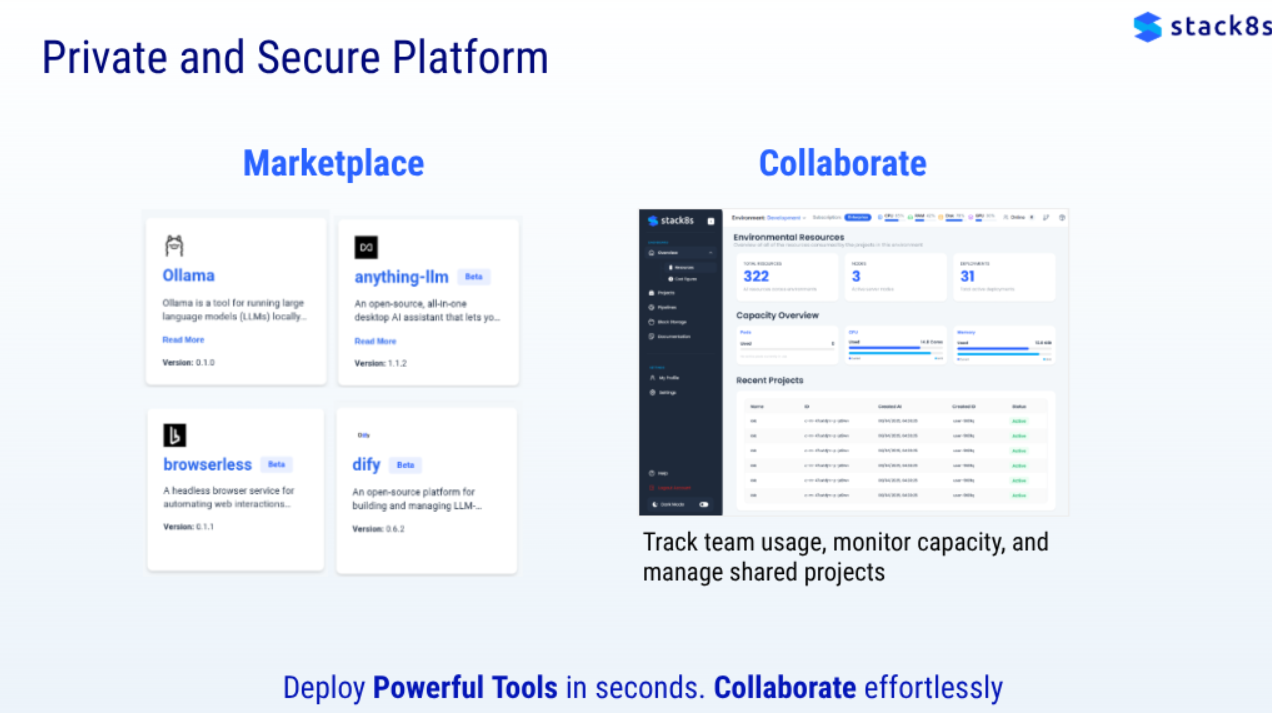
Flexible Resource Scaling
Research institutions can dynamically scale computational resources based on project requirements without the capital investment traditionally required for HPC infrastructure expansion. The platform allows institutions to burst into cloud resources during peak computational periods while maintaining baseline capacity on-premises.
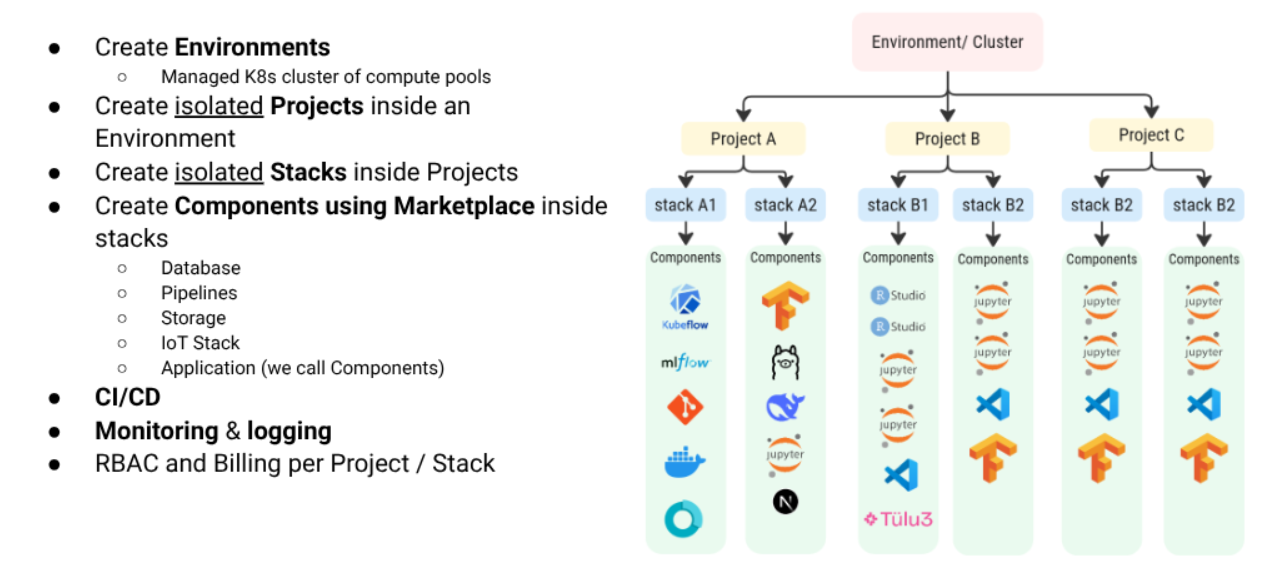
Integrated Development and Production Environments
Stack8s provides sandbox environments for research development alongside production workloads, enabling researchers to test and validate computational models before deploying them at scale. This integrated approach streamlines the research workflow from prototype development to full-scale analysis.
Comparison with Leading University HPC Platforms
SLURM-Based Systems
Most research institutions utilize SLURM (Simple Linux Utility for Resource Management) for job scheduling and resource management on traditional HPC clusters. While SLURM excels at managing homogeneous compute nodes and traditional HPC workloads, Stack8s offers superior flexibility for heterogeneous computing environments and cloud integration. Stack8s eliminates the complexity of managing multiple SLURM clusters across different locations while providing native support for containerized workloads that many research applications increasingly require.
PBS Professional and Torque
Public Broadcasting Service Professional and Torque represent mature job scheduling solutions widely deployed in academic environments. These systems provide robust job management for traditional HPC workloads but lack the cloud-native capabilities and distributed architecture that Stack8s offers. Stack8s addresses the limitations of these legacy systems by providing seamless integration with cloud resources and modern containerization technologies without requiring extensive reconfiguration of existing workflows.
LSF and Grid Engine
Platform LSF and Sun Grid Engine serve as enterprise-grade job schedulers common in larger research institutions. While these platforms offer advanced features for resource management and job scheduling, they typically require significant administrative overhead and specialized expertise. Stack8s reduces operational complexity through its AI-powered management capabilities and unified interface, allowing research computing staff to focus on supporting researchers rather than managing infrastructure complexity.
Open OnDemand and JupyterHub
Many institutions deploy Open OnDemand or JupyterHub to provide web-based access to HPC resources and interactive computing environments. Stack8s-Portal incorporates similar user-friendly interfaces while extending capabilities to distributed infrastructure management. The platform provides researchers with intuitive access to computational resources without requiring specialized knowledge of underlying infrastructure management tools.
Strategic Advantages for Research Institutions
Cost Optimization
Stack8s enables research institutions to optimize computational costs by leveraging a combination of on-premises resources, cloud computing, and collaborative partnerships. Institutions can reduce capital expenditure on HPC hardware while maintaining access to high-performance computing capabilities through the platform's distributed architecture.
Enhanced Collaboration
The platform facilitates multi-institutional research collaborations by providing secure, standardized access to shared computational resources. Researchers can collaborate on projects requiring significant computational power without the traditional barriers associated with accessing external HPC facilities.
Modern Software Development Practices
Stack8s supports contemporary software development and deployment practices that align with modern research computing trends. The platform enables research teams to adopt containerization, continuous integration, and cloud-native development practices that improve research reproducibility and collaboration.

Reduced Administrative Overhead
Research institutions can reduce the administrative burden associated with managing traditional HPC infrastructure through Stack8s automated management capabilities and unified interface. This reduction in operational complexity allows research computing staff to focus on supporting research objectives rather than infrastructure maintenance.
Implementation Considerations
Research institutions considering stack8s as an alternative to traditional HPC platforms should evaluate their specific computational requirements, existing infrastructure investments, and research collaboration needs. The platform offers particular advantages for institutions seeking to modernize their research computing infrastructure while maintaining flexibility and cost effectiveness.
The transition from traditional HPC platforms to stack8s requires careful planning to ensure compatibility with existing research workflows and data management practices. Institutions should consider pilot implementations to validate the platform's suitability for their specific research computing requirements before full-scale deployment.

stack8s.ai - It's time to take control of your own cloud