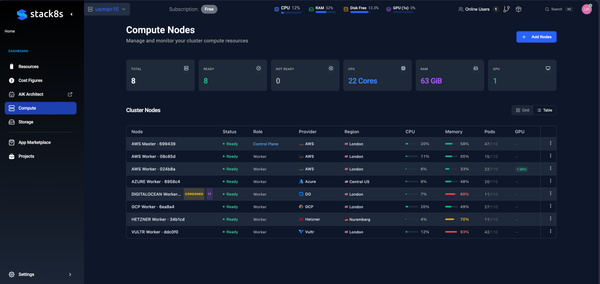
If you're pricing an AI cluster in March 2026, the names can feel like a trap. H100 SXM5, H100 PCIe, and H100 NVL all say "H100", so they must behave the same, right? In practice, the module, power limit, memory bandwidth, and GPU-to-GPU links change what